If not already clear, Markov Chain Monte Carlo (MCMC) is a tool for implementing Bayesian analyses. Pardon me? If that doesn’t make sense, please stay with me; otherwise, please skip ahead.
Bayesian statistics is just an alternative paradigm to how students are usually first taught statistics, called Frequentist Statistics.
While some might debate you on this, a common perspective is that neither Bayesian nor Frequentist statistics is necessarily better; what’s most important is one recognizes that they are different in implementation but, more importantly, different in their philosophy, the nuances of which will not be covered here. While Frequentist vs Bayesian Statistics is an important discussion, it is also not something you can knock out in 5 minutes. For an extremely brief comparison, see the table below on the difference in Frequentist vs. Bayesian statistics.
Comparison Table
Bayesian vs. Frequentist Statistics
Frequentist
Bayesian
Answer given
Probability of the observed data given an underlying truth
Probability of the truth given the observed data
Population parameter
Fixed, but unknown
Prob. distribution of values
Outcome measure
Probability of extreme results, assuming null hypothesis (P value)
Posterior probability of the hypothesis
Weaknesses
Logical inconsistency with clinical decision-making
Subjectivity in priors' choice; complexity in PKPD modeling
MCMC - for the sake of keeping things simple - is a means of sampling a target distribution to arrive at empirical posterior marginal distributions for our parameters of interest, where the target distribution is the distribution that we assume the population response to be following. What’s Notable about MCMC is that it does not require an envelope to sample the target distribution due to the Markov property. In addition, with MCMC, we can arrive at empirical posterior marginal distributions for the parameters of interest without needing conjugate priors.
Practically, this means there is ample software people can use to do Bayesian analysis using MCMC without needing to know the statistical theory that allows for it to work in the first place. With regard to reducing barriers to entry, this is a big deal! However, understanding how algorithms work is crucial! It helps data scientists make informed decisions about the choice of models and algorithms, ensuring the robustness and accuracy of their analyses. Moreover, Understanding the underlying mechanics of MCMC also aids in diagnosing convergence issues and interpreting the results correctly.
Now, on with the post!
Agenda
The purpose of this post is to demonstrate how to implement the Metropolis-Hastings MCMC algorithm from scratch for a multiple linear regression.
The First implementation will be designated implementation (a); after that, I will add more complexity but also realism in implementations (b) through to (c), mirroring something closer to canned software such as Jags and BUGS. Let’s break down some of the first steps.
Sample a candidate value X∗ from a proposal distribution g(⋅∣x(t)).
Compute the Metropolis-Hastings ratio R(x(t),X∗), where
R(u,v)=f(u)g(v∣u)f(v)g(u∣v).
Note that R(x(t),X∗) is always defined, because the proposal X∗=x∗ can only occur if f(x(t))>0 and g(x∗∣x(t))>0.
3. Sample a value for X(t+1) according to the following:
X(t+1)={X∗x(t) with probability min{R(x(t),X∗),1}, otherwise.
library(here)dat = read.csv(here("data","bodyfat.csv"));n = nrow(dat)y = dat[,1]; X = as.matrix(cbind(Int = rep(1,n),dat[,-1]))p = ncol(X); n.s = 100000; k = p - 1; ee = 1e-16par_names <- c(paste0("beta_", 0:13),"sigma_sq")
The data is on the percent body fat for 252 adult males, where the objective is to describe 13 simple body measurements in a multiple regression model; the data was collected from Lohman, T, 19923 .
Potential Predictors of Body Fat - Data from Lohman, T, 1992
Using the Jeffreys prior (an improper prior), we can implement a Random Walk Chain with Metropolis-Hastings Markov Chain Monte Carlo to sample the Normal target distribution where Jeffreys prior is defined as
We will start off with a simpler implementation, which we will denote Implementation (a) with manual scaling, Single Chain, Burn-in, No thinning, and a Jeffrey’s Prior.
First, I will present the code and then explain the details see the foldable code chunk (a), below (Note: the box below is a folded code chunk; click the arrow to expand )
(a): manual scaling, Single Chain, Burn-in, No thinning, and a Jeffrey's Prior
library(mvtnorm)np <- length(opt$par)n.s = 100000; draws = matrix(NA, n.s, np)draws[1, ] = opt$par; C = -solve(opt$hessian)scale_par = .45; burnin = 500; set.seed(23) for (t in 2:n.s) { u = runif(1) prop <- rmvnorm(1, mean = draws[t-1, ], sigma = scale_par*C) if (u < exp(lpost(prop) - lpost(draws[t-1,]))) { # acceptance ratio draws[t, ] = prop # accept # } else { draws[t, ] = draws[t -1, ] }} # reject #tab.MCMC.a <- t(apply(X=draws[-c(1:burnin),],MARGIN = 2,FUN = samp.o))row.names(tab.MCMC.a) <- par_names; tab.MCMC.a(acc.a = (apply(draws[-c(1:burnin),],2,function(x) length(unique(x))/length(x)))[1])
To start, Implementation (a) uses Jeffrey’s Prior, which is an improper, vague prior; it is improper because its integral does not sum to 1, which is a requirement for valid PDFs. However, its density function is proportional to the square root of the determinant of the Fisher information matrix:
p(θ)∝detI(θ)
As already stated, Jeffrey’s Prior is vague prior, which is also known as a flat, or non-informative prior. Vague priors are guaranteed to play a minimal role in the posterior distribution.
We are using the multivariate normal distribution with rmvnorm to generate proposal values for each of the parameters, and scaling the variance covariance matrix C by scale_par to help adjust the acceptance ratio towards the optimal acceptance rate of 23.4 that holds for inhomogeneous target distributions π(x(d))=Πi=1dCif(Cixi) (Roberts and Rosenthal, 2001)4.
For Implementation (a), we get an acceptance ratio of 0.2267; this was achieved in part by manually choosing scale_par to get an acceptance ratio closer to the target of 0.234.
Below, we can print our results
tab.MCMC.a
Parameters
Mean
SD
Lower
Upper
beta_0
-18.043
20.961
-58.974
23.104
beta_1
0.057
0.031
-0.003
0.118
beta_2
-0.087
0.058
-0.200
0.029
beta_3
-0.035
0.166
-0.356
0.290
beta_4
-0.431
0.222
-0.868
0.009
beta_5
-0.015
0.096
-0.201
0.175
beta_6
0.889
0.085
0.719
1.052
beta_7
-0.194
0.139
-0.470
0.075
beta_8
0.241
0.138
-0.026
0.512
beta_9
-0.025
0.234
-0.492
0.433
beta_10
0.166
0.212
-0.251
0.585
beta_11
0.155
0.162
-0.162
0.470
beta_12
0.429
0.187
0.068
0.805
beta_13
-1.484
0.509
-2.490
-0.498
sigma_sq
16.156
1.476
13.479
19.295
Reminder
The posterior distribution is what we get out of a Bayesian analysis; we get one distribution for each parameter, Not, a single point estimate, as is the case with frequentist statistics. Hence see beta_3 Posterior below.
Thus, We can plot the posterior distribution for Weight (β3), in which case we can see that the mode of the distribution is similar to the mean point estimate presented in the table above (-0.036).
Next in Implementation (b), instead of using a Jeffries Prior, we can create priors_list, and specify a prior for each parameter.
(b): Manual scaling, Single chain, Burn-in, No thinning, Uniform and Normal priors
priors_list <- list( function(theta) dnorm(theta, mean = 0, sd = 1000, log = TRUE), # beta_0 Prior function(theta) dnorm(theta, mean = 0, sd = 1000, log = TRUE), # beta_1 Prior function(theta) dnorm(theta, mean = 0, sd = 1000, log = TRUE), # beta_2 Prior function(theta) dnorm(theta, mean = 0, sd = 1000, log = TRUE), # beta_3 Prior function(theta) dnorm(theta, mean = 0, sd = 1000, log = TRUE), # beta_4 Prior function(theta) dnorm(theta, mean = 0, sd = 1000, log = TRUE), # beta_5 Prior function(theta) dnorm(theta, mean = 0, sd = 1000, log = TRUE), # beta_6 Prior function(theta) dnorm(theta, mean = 0, sd = 1000, log = TRUE), # beta_7 Prior function(theta) dnorm(theta, mean = 0, sd = 1000, log = TRUE), # beta_8 Prior function(theta) dnorm(theta, mean = 0, sd = 1000, log = TRUE), # beta_9 Prior function(theta) dnorm(theta, mean = 0, sd = 1000, log = TRUE), # beta_10 Prior function(theta) dnorm(theta, mean = 0, sd = 1000, log = TRUE), # beta_11 Prior function(theta) dnorm(theta, mean = 0, sd = 1000, log = TRUE), # beta_12 Prior function(theta) dnorm(theta, mean = 0, sd = 1000, log = TRUE), # beta_13 Prior function(theta) dunif(theta, min = 1e-6, max = 40, log = TRUE) # sigma_sq Prior)# Function to calculate the total log priorlog_prior_func <- function(theta, priors_list) { log_prior_values <- mapply(function(theta_val, prior_func) prior_func(theta_val), theta, priors_list) sum(log_prior_values)}# Modify lprior to use the log_prior_funclprior <- function(pars) log_prior_func(pars, priors_list)# Modify lpost to include the new lpriorlpost <- function(pars) llike(pars) + lprior(pars)for (t in 2:n.s) { u = runif(1) prop <- rmvnorm(1, mean = draws[t-1, ], sigma = scale_par*C) if (u < exp(lpost(prop) - lpost(draws[t-1,]))) { # acceptance ratio draws[t, ] = prop # accept # } else { draws[t, ] = draws[t -1, ] }} # reject #tab.MCMC.b <- t(apply(X=draws[-c(1:burnin),],MARGIN = 2,FUN = samp.o))row.names(tab.MCMC.b) <- par_names; tab.MCMC.b(acc.b = (apply(draws[-c(1:burnin),],2,function(x) length(unique(x))/length(x)))[1])
Notice we print a summary table of the posterior distributions, the point estimates we get our different from Implementation (a). Note, we also get a different acceptance rate of 0.227.
tab.MCMC.b
Parameters
Mean
SD
Lower
Upper
beta_0
-17.891
20.698
-57.690
23.028
beta_1
0.056
0.030
-0.003
0.116
beta_2
-0.086
0.058
-0.197
0.028
beta_3
-0.037
0.167
-0.363
0.289
beta_4
-0.435
0.222
-0.871
-0.005
beta_5
-0.017
0.098
-0.208
0.176
beta_6
0.891
0.084
0.726
1.055
beta_7
-0.195
0.138
-0.469
0.075
beta_8
0.233
0.138
-0.041
0.498
beta_9
-0.020
0.232
-0.472
0.433
beta_10
0.171
0.207
-0.231
0.575
beta_11
0.159
0.162
-0.155
0.474
beta_12
0.432
0.188
0.053
0.797
beta_13
-1.480
0.499
-2.459
-0.499
sigma_sq
16.226
1.465
13.655
19.338
The next layers of complexity we will add for Implementation (c) are thinning, multiple chains, and Adaptive Scaling.
Notice that the point estimate we get from the samp.o of our posterior distributions is again different from Implementation (a) and Implementation (b). Note, the acceptance rates for the three chains where 0.109, 0.182, and 0.107.
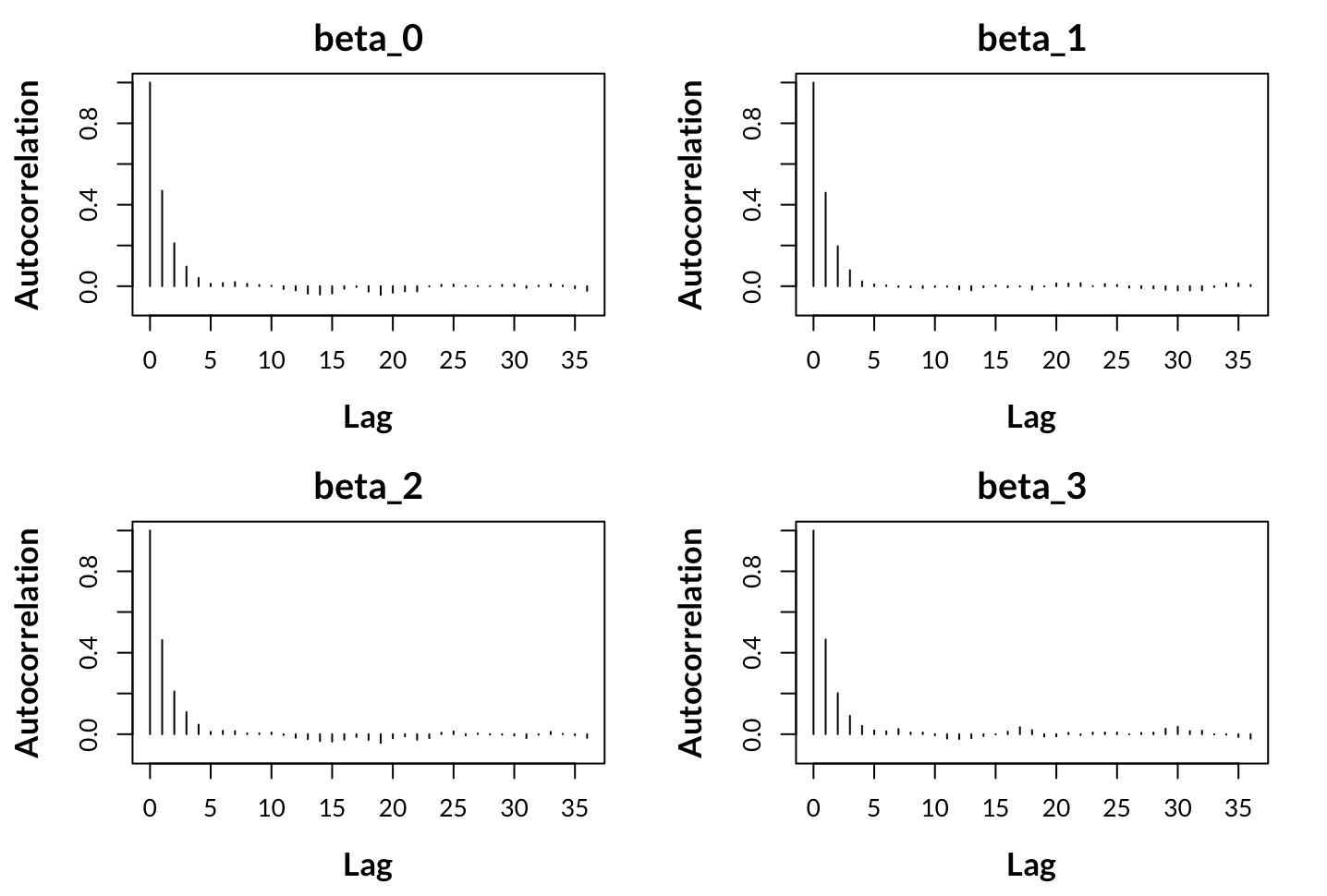
Thinning is a process that is done to help reduce the autocorrelation present in the chains; if there is severe autocorrelation, then the results are not usable for inference. Autocorrelation in the chains is usually diagnosed with an autocorrelation plot. Looking at the autocorrelation for (c), we can see that there is still some concerning autocorrelation (we want almost no spikes for the first half dozen lags); thus, via bumping up the argument thinning to be something higher than 20, say 40, we might resolve the issue of autocorrelation.
old_par <- par()par(mfrow = c(2,2), mar = c(4.5, 4.5, 2.5, 2),font.lab = 2)xacf <- list()for (i in 1:4){xacf[[i]] <- acf(mcmc.out$chains[[1]][, i], plot = FALSE)plot(xacf[[i]]$lag,xacf[[i]]$acf, type = "h", xlab = "Lag",ylab = "Autocorrelation", ylim = c(-0.1, 1),cex.lab = 1.3, main = par_names[i], cex.main = 1.5)}par(old_par)
Autocorrelation Plot for (c): 1 chain, first four parameters
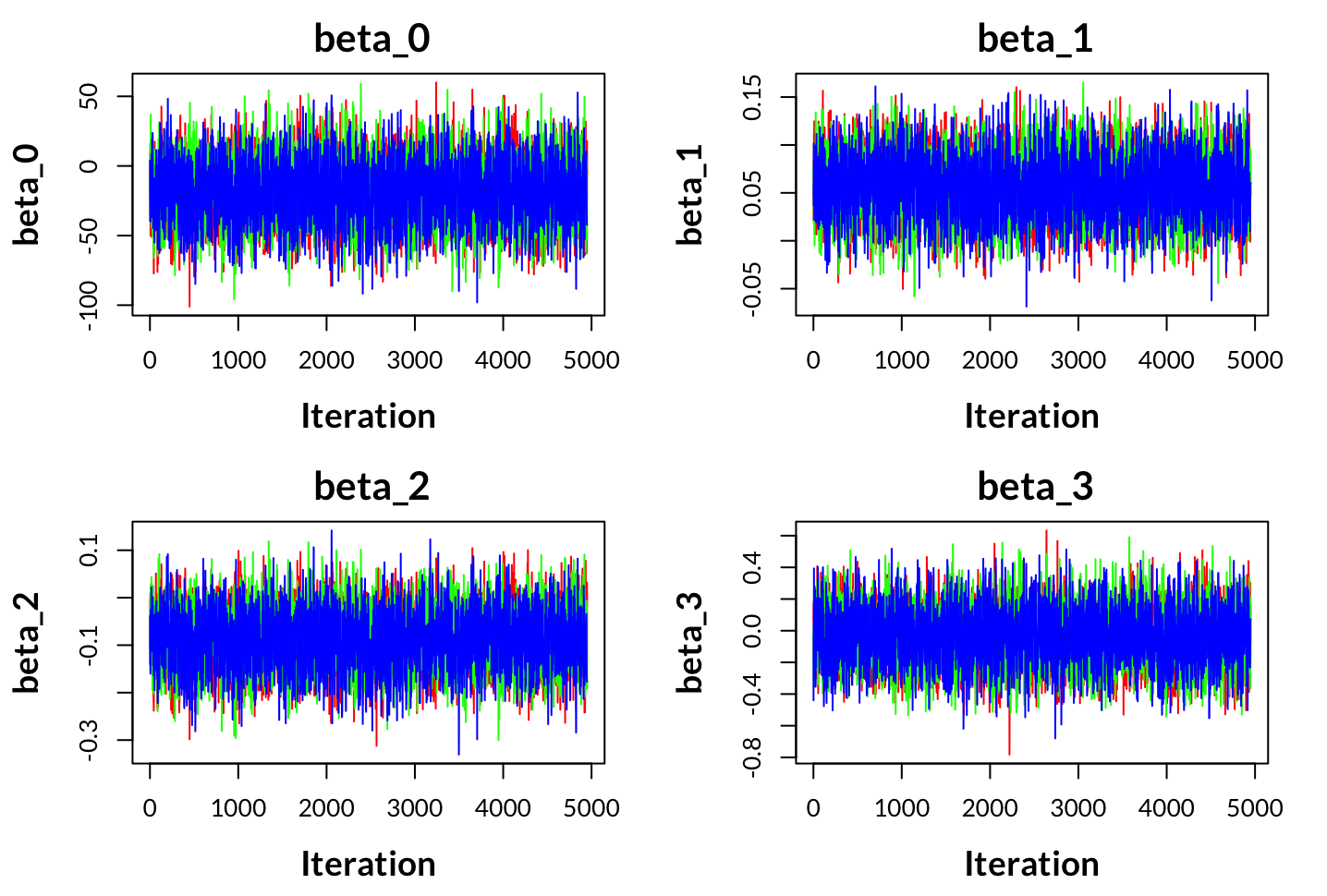
With adding multiple chains, we have just added an extra loop (in this case, iterating over j) to repeat the same sampling procedure for each chain. The traceplots below show good mixing for the first four parameters. If the respective traceplots for each parameter show good mixing of chains, this indicates that the MCMC algorithm converged, and given no problems of autocorrelation, the results are usable for inference.
Traceplot for (c): 3 chains, first four parameters
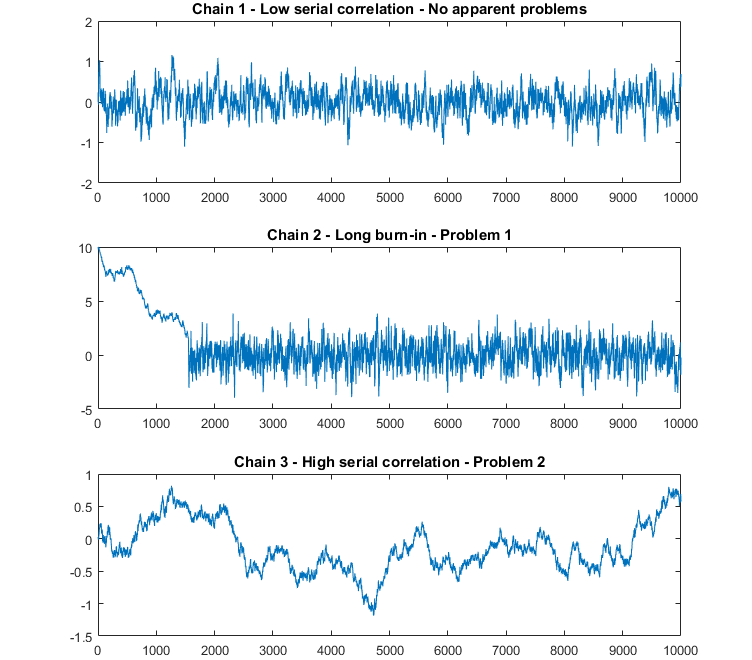
For reference, the image below shows a good mixing of the first chain, indicating convergence, while chain 2 initially shows the chain has not converged until around iteration 1500 and chain 3 never converges. However, a caveat of this plot is that the chains are on different plots. Ideally you want to use a traceplot that shows all chains for a respective parameter on the same plot. Hence, the word mixing is referring to the fuzzy caterpillar-looking image shown in Traceplot for (c)
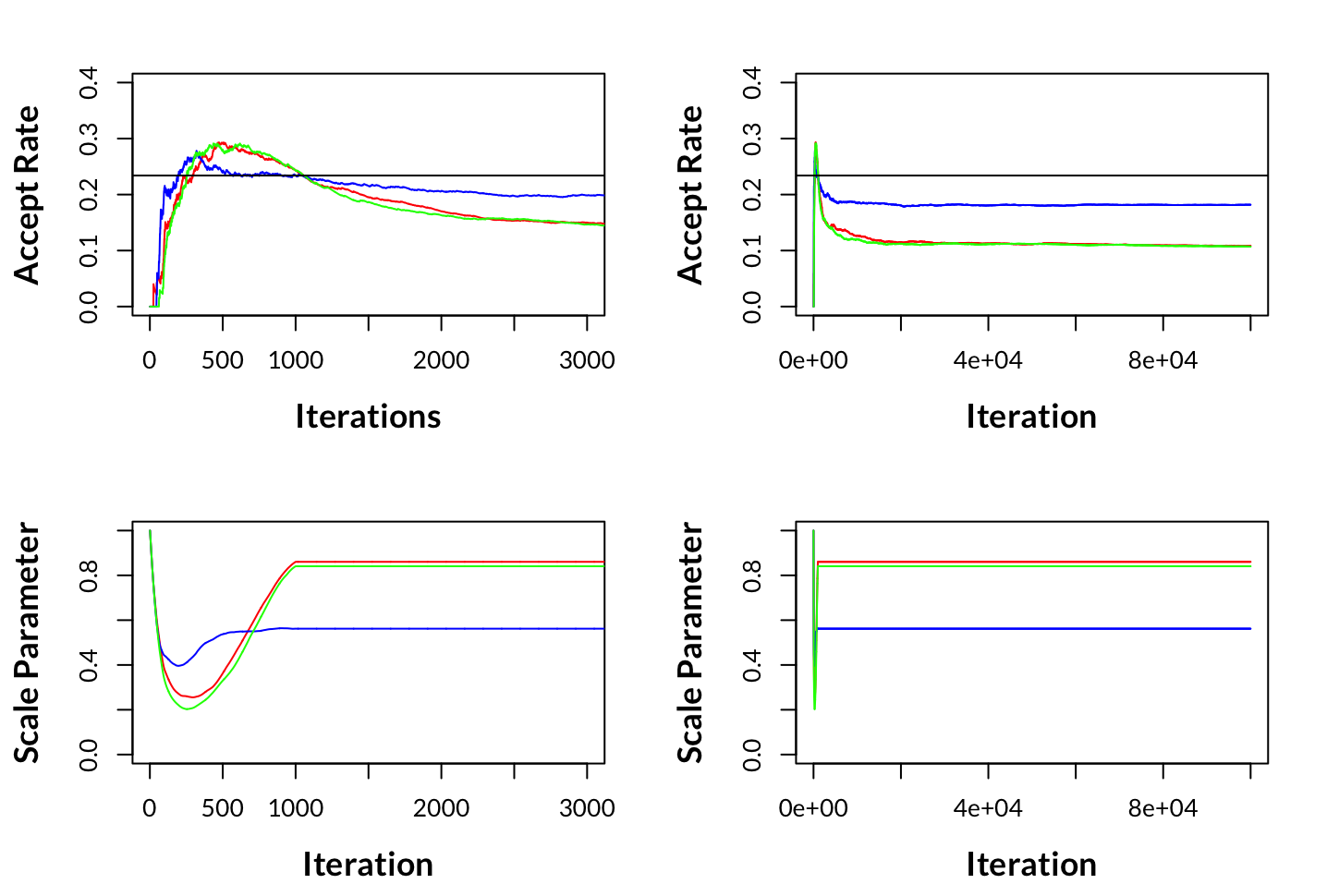
Adaptive Scaling is a hand-off approach to adjusting a scaling term (which I named scale_par i the code), which in terms scales the variance-covariance matrix C. The purpose of this scaling is specific to the accept-reject methodology inherent in Metropolis-Hastings MCMC. As there is no knowing what the Acceptance rate will be before running the algorithm as the process is stochastic and is subject to your data, likelihood, and priors. Notice in Implementation (a) we set scale_par, but in practice, this involved rerunning MCMC multiple times adjusting scale_par each run, trying to get an acceptance rate close to the ideal acceptance rate of 0.234. As shown in MCMC Acceptance Rate Scale Parameter for (c).
Now we are adjusting scale_par dynamically based on the acceptance rate of the proposals during the sampling process. The idea is to increase scale_par if the acceptance rate is too high (indicating that the chain is making too many small, cautious steps) and decrease it if the acceptance rate is too low (indicating that the chain is making too many large, risky steps). scale_par is adapted during the burn-in period. The adaptation is based on the difference between the current acceptance rate and the target acceptance rate (target_acc_rate of 0.234). The learning_rate controls the speed of adaptation. After the burn-in period, the scale_par remains constant for the rest of the sampling. This approach should help achieve a better balance between exploration and exploitation in the parameter space, improving the efficiency of the MCMC chain.
However, there is a caveat: after burn-in, scale_par is no longer being adjusted, and yet the acceptance rate continues to drift below 0.0234 until each of the chains converges. Perhaps you might think to yourself, “Then why don’t you leave scale_par to be adjusted after burn-in as well, then our acceptance rate will still hover close to 0.234”; no doubt some readers will know the answer. We can’t continue to adjust scale_par after burn-in, or we would be breaking the Markov Property subsequently, making our results theoretically invalid; moreover, the chains might never converge if C was continually adjusted by scale_par.
The Markov Property
One of the fundamental properties of MCMC algorithms is the Markov property, which states that the next state of the chain depends only on the current state and not on how it arrived there.
P(Xt+n=x∣Xt,Xt−1,…,Xt−k)=P(Xt+n=x∣Xt)
Hence, adaptive scaling is not perfect; although we can lift the acceptance rate from minuscule digits below 0.001 to above 0.1 (see the top right plot of MCMC Acceptance Rate Scale Parameter for (c)), we still don’t land within a very close distance of the ideal acceptance rate of 0.234. Really, what we have achieved is giving the chains a better starting location post-burn-in in terms of acceptance rates so that when it does converge, it’s hopefully a stone’s throw away from 0.234. From my research, other Adaptive scaling methods have the same problem (see RAM).
MCMC Acceptance Rate Scale Parameter: iterations 0 to 3000 and 0 to 100000
Note
A more popular method for Adaptive scaling is Robust Adaptive Metropolis (RAM). However, to avoid the need for Adaptive Scaling altogether, Gibbs Sampling is another very popular MCMC procedure that uses conditioning to avoid an acceptance rate and, subsequently, the need for Adaptive Scaling.
All of the code is available in the directory content/scripts/Metropolis_Hastings_MCMC_from_Scratch at my repo, with bonus content of implementations (d), and (e).